Composr Tutorial: The Composr Enterprise Repository
Written by Chris Graham
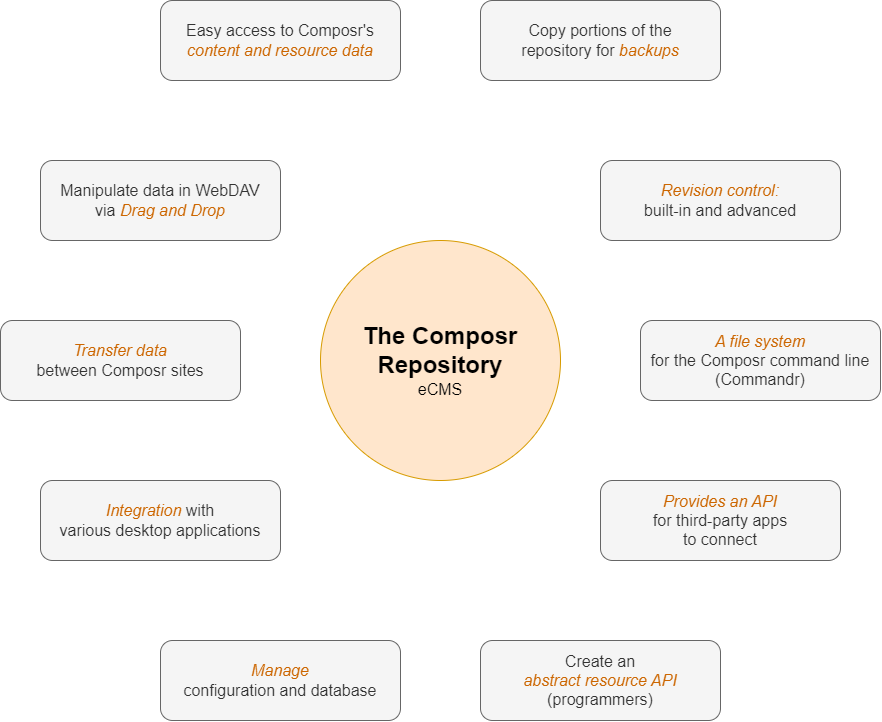 The Composr repository is a shadow representation of Composr's data.
The Composr repository is a shadow representation of Composr's data.In most cases, Composr data is stored in the database, which is not a particular user-friendly form, given databases are generally designed with a special set of rules that lead to data being split up across multiple tables. Sometimes data is also stored on the filesystem (i.e. the disk); for example, file uploads.
The Composr repository represents the data into a form that feels far more natural and integrates with many kinds of tools you may want to use on it. Most of the data is encoded using the JSON standard.
Through WebDAV (needed for most of the use cases below) you can access the repository as a folder on your own computer.
Specifically, the following use-cases are served by the repository:
- Making Composr opaque – dive right into Composr's content/resource data and get an immediate sense of what is there and how it is structured
- Making Composr tactile – easily manipulate data via normal drag & drop operations without a clunky and slow web interface; for example, mass move entries from one category to another, or mass-delete all entries under select categories (which may or may not include removing the categories as well)
- Making transferring data between sites (e.g. from a staging site to a live site) easier – copy & paste from one site to another and Composr will magically import everything, reassign ID numbers as required, auto-match named categories where possible, and create empty-shells for missing dependencies as required
- Integration with normal desktop applications – use your favourite text editors or file-search tools to achieve things such as mass search & replace
- Configuration management – track what options have been changed, and transfer them between sites
- Backups – copy portions of the repository to another location for backup; for example, if you are about to make major changes to the catalogue structure, take a backup of the catalogues
- Revision control (built-in) – content types supporting the revisions system can save the full data of any edited or deleted resource, for retrieval later
- Revision control (advanced) – hook up Git to the repository directory, either locally, on your server, or both, to backup content as it is modified
- A file system for the Composr command line (Commandr)
- Creating an abstract resource API (for programmers) – by having a resource model that is abstract (i.e. it's a single model that can be used for manipulating any kind of content/resource), programmers can come up with some clever functionality; Aggregate Content Types is an example of Composr functionality that is built on top of the repository
- An API for separate apps (e.g. mobile apps) to connect through to
And the following work-in-progress use-cases:
- Making content/resource import and export very easy – we are able to code up import/export support into the repository by coding in additional views of the same data; for example, we would be able to allow automatic import of images into galleries via just copying in JPEG files
Table of contents
The filesystem
The repository is actually implemented within Composr as the Commandr-fs filesystem. Commandr-fs and the repository are one and the same. You therefore must have Commandr installed for it to be available.The repository consists of a number of meta-filesystems, each tied into the filesystem at a particular mount point, with the mount points inspired by UNIX filesystem design.
The default meta-filesystems are as follows, and are all mounted as subdirectories of the root directory:
- bin: A place to store all your Commandr scripts
- database: Access to the raw relational database; level 1: tables, level 2: rows (identified by ID)
- etc: Access to Composr configuration options
- home: Access to the filedump (aka the File/Media Library)
- filedump: Access to the filedump (aka the File/Media Library); will be JSON with metadata if available, otherwise a raw file
- members: A listing of every member registered on the system, with their account/profile settings and usergroups
- raw: A raw listing of the actual Composr installation directory
- root: A listing of the Composr installation directory, taking source code overrides into account with higher precedence than original files (featuring automatically overriding when files are edited)
- Caveat: This does not take into account contentious_overrides hooks because these overrides often implement logic to determine when the override applies. This makes it impractical to compile.
- var: Structured website resources/content, separated by resource type on level 1, with category structure as further folders (generally-speaking), and entries as JSON files
The var meta-filesystem is perhaps the most interesting because if Webdav is installed, you can use this to import/export/copy resources/content into and between websites using your normal desktop file manager (with some caveats as mentioned further down). This is extremely useful. In actuality, var is not a meta-filesystem in its own right, each directory underneath it is implemented as a separate meta-filesystem.
WebDAV
WebDAV software

(Click to enlarge)
Be aware that some operating systems do not support WebDAV very well in practice. The SabreDAV team have excellent documentation illustrating issues that are outside our control, and in most cases third-party software can be used for a better experience:
- On Mac Finder has some slowness issues. Cyberduck works well, but doesn't currently provide a way to mount to a folder. Yummy FTP Pro works on HTTP but not HTTPS.
- On Windows, you may want to use NetDrive to mount WebDAV, as Windows has some issues (some versions of Windows cannot run a share off a subdirectory, basic authentication needs a registry patch to make it work, and you have to disable "Automatic Detect Settings")
- You can use BitKinex, NetDrive, WinSCP, or Cyberduck, but only NetDrive can mount to a directory
- If you use BitKinex: you need to ensure you specify your WebDAV folder is a folder, not a file (it may default to a file, which is a bit odd)
- If using the native Windows client, you do it via mapping a network drive. You need to first ensure the WebClient service is not disabled, and is started, and that the registry is patched to allow basic authentication, and that "Automatic Detect Settings" is disabled.
- On Linux, the KDE and Gnome clients and davfs should work well, but this has not been tested
Access WebDAV by connecting to: http://yourbaseurl/webdav, or http://webdav.yourbaseurl if you've configured a webdav subdomain to point to your base directory.
You will need to enable this by the association rewrite rule in our recommended configuration.
You will need to authorise against a Composr administrative user.
- Note: Some WebDAV clients like Cyberduck do not like usernames with spaces in them. Make sure your administration accounts are alpha-numeric usernames only.
Nginx reverse proxy
If you are using an Nginx reverse proxy you may need to comment out or remove some code from your site's configuration:This code is supplied by default on Plesk servers and provides directory index handling at the nginx level. Unfortunately we need to handle this within our WebDAV implementation. The code takes precedence over the nginx code block doing the proxying, so you have to remove this whole block to re-enable proxying on any URLs with trailing slashes.
The var meta-filesystems
Everything under var is known as Resource-fs, as it is built on a special API within Composr.Each meta-filesystem under var is structured using filenames and (sometimes) folders. There is an assumption that everything under one of these meta-filesystems is of a particular set of resource types.
The filenames are not based upon ID numbers usually used for addressing in Composr, and relationships between them are not either. There are two reasons for this:
- Friendly naming, for the human browsing the filesystem
- So dependencies can be encoded knowing that IDs may not match up, or conflict, between sites
Every file or folder in a filesystem is a Composr "resource". In most cases, every file or folder is a content item. Things like multi-moderations or post-templates are resources, but not content, which is why we hold the distinction.
Addressing
Each resource has a number of addressing methods:- resource-type and resource-ID combination
- label
- moniker
- filename
- GUID
Composr maintains a database table that ties all the different addressing schemes together.
Resource-type and resource-ID combination
Within normal Composr code, resources are addressed by the resource-type and resource-ID combination. For example, download and 4. Sometimes the resource-type is not needed, when the code involved implicitly knows what resource-type it is working with (e.g. if you're working within the downloads module, it clearly knows IDs refer to downloads).The resource/content-types are defined by the PHP files in the sources/hooks/systems/resource_meta_aware and sources/hooks/systems/content_meta_aware directories.
The repository internally has a sense of resource-type and resource-ID combination for looking up data, but all communication actually works via one of the other methods. This is so that we can transfer data between different sites without having the sequential ID numbers failing to match up correctly.
Label
Each kind of resource has a label, and the meaning of this differs from resource to resource. Generally though, it is the human-readable title of it.The repository has an internal API for adding and referencing resources by label, which is used by some Composr code.
Moniker
The label is too free-form to be used for file names, so we actually convert it automatically into a 'moniker'. This is similar to Composr's 'URL monikers' system, but actually the repository uses its own set of monikers. A moniker is guaranteed to be generated as unique across the whole filesystem, while of course a label may not be (we could imagine two entries in a category with the same label for example).Filename
Once we have a moniker, this essentially then is combined with the file extension (if applicable – not for folders), to form the filename. Usually the file extension is .cms. Because monikers are unique, filenames are actually unique and we know we will never get conflicting names.Because entries are usually represented as files within folders (categories), we can therefore think of resources as being identified via a full file path, which is essentially a combination of monikers and slashes (/ on Mac/Linux, \ on Windows).
Obviously an entry's category is the same as the folder it is within, so the filesystem automatically carries many data relationships this way.
GUID
For the remaining cases where we have relationships between resources that are not carried by directory structure, we encode it using multiple addressing schemes stored within the .xml files, in precedence order:- GUID
- label and subpath
GUIDs are long codes, with dashes in, designed to be globally unique. This ensures that when they are generated on different sites, they won't conflict. Each resource is assigned a GUID, and when that resource is copied between sites, the GUID is preserved – which allows us to match things up, even though ID numbers will not match up.
If we copy something from one site to another, and can't get a GUID match, we try and get a label match. This would automatically match members on different sites by having the same username, for example.
If we still cannot get a match, the label is used to create a new resource, and we'll associate with that. Any resource in the filesystems can be created by label alone, and the other fields are set as default as a result.
Comcode
It is very common to write Comcode that uses IDs directly. For example, blocks often require IDs as parameters.This presents a problem because the automatic GUID-based resolution (described under the above "Addressing" section) would not work. You'd in all likelihood get failed matches if you copied your Comcode from one site to another.
You may write GUIDs instead of IDs because Composr will substitute them for IDs prior to the main parsing of your Comcode. It will also do this for menu captions.
This works well, but of course you have to make the effort to consciously do it, as the block/Comcode assistants will continue to put in ID numbers.
There are Commandr commands to help you with this. For example:
find_guid_via_id download_category 6
would give you the GUID for download category #6.
This is a little laborious, but if you are at the technical skill level where you are copying content between multiple sites, hopefully you will also be able to be comfortable using Commandr and manually coding your Comcode. These are core Composr skills at this proficiency level.
Use care when copying
 It would be a mistake to just try and backup everything in the repository, and think you can copy it all back to a site to restore it. You should have full regular database backups for your first go-to backup technique.
It would be a mistake to just try and backup everything in the repository, and think you can copy it all back to a site to restore it. You should have full regular database backups for your first go-to backup technique.In most cases you should work just under var for this kind of thing, and you should think in terms of copying over folders and files that you know about, not everything at once. This will greatly reduce the chance of you unexpected behaviours. The system is complex and doing a lot of magic underneath the hood to make things match up – don't take it too much for granted.
Of particular note is that there may be overlap with different parts of the repository. In particular, stuff under database will overlap with stuff under var. Never think about copying stuff from directly under database from one site to another as it has no sense for how to port associated resources over and almost certainly will lead to corruption.
Don't do things like run rsync or Git over the repository as a whole – although you may have good results if you carefully focus such things on specific parts of the repository.
Incorrect reporting
You may see some files or folders quoted with a file size of zero or unknown. This happens in situations where calculating the virtual file size for everything in a directory listing would be inefficient. Usually, if you perform an operation on the file or folder (e.g. downloading, moving, copying) then WebDAV will report a correct file size for those files / folders specifically so the operation can be carried out.You may also see a file modification time of 1970. This happens when no file modification time is known.
If you manually specify the name of a folder or a file, you may find it changes when the directory refreshes. This is because it will be treated as a new label, and the moniker (and thus filename) will then be generated from that. For example, spaces would be stripped.
Known omissions / limitations
These are the current known omissions for the repository:- Listings in virtual folders such as the var directory are limited to 10,000 folders and 10,000 files at once, or however many can be processed before the server starts running out of memory or execution time.
- If you add content via the repository, no syndication will be performed for it. E.g. if you add a news article, it won't be syndicated to Facebook if you've configured such syndication. This is normal within Composr, as syndication is an automated assistant built into the CMS modules, not the underlying framework. You can always syndicate things manually if required.
- Multi-language-content translations are not retained (https://composr.app/ca…es/entry/tracker-2111.htm)
- In /var/ and /filedump/, for resources containing files (e.g. downloads), if the file is over 8 MB in size, Resource-fs will return a string path instead of a double ([path, base64 data]) for that property. This is to help prevent PHP memory errors. You can always manually download the file under /raw/ or /home/ (if it is particularly large, even this may trigger a memory error; use FTP instead). Also, you should not try uploading files to the Resource-fs repository that are over 8 MB in size or you may get a PHP memory error; upload it via FTP, usually to the uploads directory, and then provide a relative path string instead in the relevant Resource-fs resource.
- Staging site limitations
- If importing eCommerce product configuration, the IDs for custom permission products can't be automatically remapped (https://composr.app/ca…es/entry/tracker-2113.htm)
- For custom fields representing IDs, the IDs can't be automatically remapped (https://composr.app/ca…es/entry/tracker-2125.htm)
- For config option values representing IDs, the IDs can't be automatically remapped (https://composr.app/ca…es/entry/tracker-2126.htm) – but in most cases names (e.g. forum names) can be used instead of IDs, mitigating the problem
- Transferring members
- For an imported member's category-level notifications, the IDs can't be automatically remapped (https://composr.app/ca…es/entry/tracker-2114.htm)
- Member signature attachments cannot transfer (https://composr.app/ca…es/entry/tracker-2127.htm)
These limitations only affect particularly advanced/fringe usage, mainly those wanting perfect automatic staging site transference on complex data schemas. If you are an enterprise pushing things to the very edge, you'll likely want to sponsor some continued development. This cost would be tiny compared to normal enterprise CMS licensing costs.
Generally Resource-fs is not designed for merging separate websites into one. There is a separate merge importer in Composr to handle this use case; it has been more thoroughly tested for site merging and better handles nuances (e.g. ID re-mapping, language translations, the transferring of attachments and uploads, fixing Comcode).
Concepts
- Repository
- The user-friendly feature name for the way of accessing Composr data as folders/files
- Commandr-fs
- The technical name for the repository implementation
- Meta-filesystem
- One of the hooks in the filesystem that implements a particular subfolder of the overall folder structure
- Resource-fs
- The name for the Composr system that both serves the 'var' meta-filesystem and also provides a resource-agnostic API within Composr
See also
Feedback
Please rate this tutorial:
Have a suggestion? Report an issue on the tracker.